

Cloud computing is a resource that is becoming more affordable, efficient, and widespread in today’s enterprise environments. Having a well-hardened environment will thwart most attacks on your organization’s assets and resources, but what happens when an S3 bucket that your team created years ago was misconfigured along the way and auditing of the security configuration was not properly conducted?
A cloud communication platform found out the answer the hard way when one of their S3 buckets was not configured with the appropriate access policies. An attacker was able to execute code after a member of their team adjusted the IAM policies while troubleshooting a problem with one of their build systems and the permissions were not properly reset once the issue had been resolved. This allowed the attacker to alter some of the SDK code that was ultimately downloaded by their clients.
Being able to effectively monitor and investigate AWS events is not only vital to your cloud security, but also your company’s reputation.
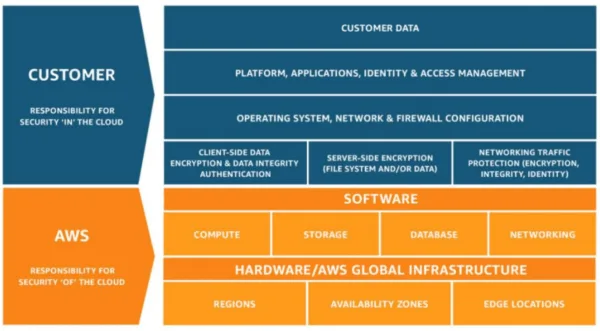
A breakdown of the shared responsibility between AWS and the customer
AWS is responsible for protecting their infrastructure but it is the customer’s responsibility for protecting their data in the cloud by applying the appropriate identity and access controls. If we were to break this down to the CIA triad (Confidentiality, Integrity, and Availability), the customer would be responsible for the data’s confidentiality by controlling access to the data, AWS would be responsible for the availability of the data, and it is a joint responsibility of AWS and the customer to maintain the integrity of the data by having policies in place to prevent tampering.
Tips for Monitoring AWS Cloud Activity
To be able to effectively perform investigations within AWS, you need a way to effectively audit AWS events. An event is defined as any observable occurrence in a system or network. Enabling service and application logging for all AWS accounts will provide non-reputability and greatly assist your team in deep diving into security incidents.
Build custom alerts by combining AWS CloudWatch and CloudTrail
AWS CloudWatch is an AWS service that is designed to provide you the ability to monitor various metrics and configure alarms based on data from those metrics. There is also the ability to generate composite alarms which build off metric-based alarms and other composite alarms.
AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS accounts. Utilizing CloudTrail logs, you can begin capturing events by recording every API call and storing them in an encrypted S3 bucket for auditing and investigative purposes.
AWS CloudTrail provides the ability to send trails to multiple buckets. One bucket should only be able to be accessed by your security team or when auditing is necessary. If your workflow requires, you can generate additional trails that will send another copy of logs to another, more accessible S3 bucket.
Combining AWS CloudTrail metrics with AWS CloudWatch alarms allow you to build out custom alerts, which notify you of suspicious activity and provides you the ability to generate an automated response to a potentially malicious action.
The AWS Security Hub also builds off AWS CloudWatch by providing a more user-friendly approach to building alerts as well as assisting in creating automated responses.
Understanding normal behavior within your environment allows you the ability to create unique detection content when unordinary events are occurring. Utilizing a platform such as AWS CloudWatch or ReliaQuest’s GreyMatter provides the ability for custom detection content, which can generate alerts when anomalies are observed within the environment such as a large outflow of data being transferred from an S3 bucket, or alert on potentially unauthorized policies being created and assigned to objects that may indicate an attacker attempting to pivot within the environment.
Ensure IAM is properly configured
Being able to provide permissions and identify who accesses specific resources is a key element in maintaining an effective security posture within any organization. Every unique user that needs access to your AWS account should have their own IAM account. As this can become a time-intensive endeavor, it is normally more efficient to define groups that users can be a part of based on their job role. This will allow all users within that group to inherit their groups’ permissions instead of having to be individually assigned.
One of the fundamentals of assigning permissions to users is to ensure that the user has the least level of permissions required to perform their job (Principle of Least Privilege). Knowing this, it is important to audit IAM permissions frequently to ensure users maintain only the minimal permissions necessary to effectively perform their job. Configuring strong passwords and requiring MFA for all users provides an extra layer of security and helps provide nonrepudiation.
IAM does not only refer to users, but it also applies to roles that can be applied to objects. Roles do not have permanent credentials; they instead have credentials that are rotated periodically by AWS. AWS provides the ability to assign roles to EC2 instances. This allows any application running within the EC2 instance to use the same role when accessing additional AWS resources.
For developers within your organization that need Command Line Interface (CLI) access, it is important to provide unique access keys to each individual. This provides the ability to revoke the access key if necessary, with the added benefit of having another artifact to pivot on during an investigation.
IAM provides ARNs (Amazon Resource Names), which are a way to uniquely identify resources and are used by IAM to control access. An ARN will be displayed in the pattern “arn:partition:service:region:account-id:resource-type/resource-id” and is created in such a way to uniquely identify the user or object involved in the operation. This allows you to quickly disable the account if the account becomes compromised.
Below are some additional examples of the IAM Syntax:
arn:aws:iam::0123456789:root
arn:aws:iam::0123456789:user/Roboman1
arn:aws:iam::0123456789:role/S3Access
arn:aws:iam::0123456789:group/SecurityEngineers
Investigating AWS alerts with a standardized analysis process
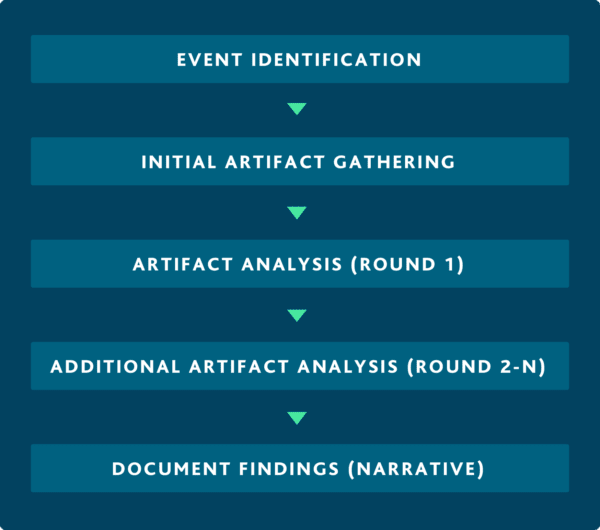
ReliaQuest’s proprietary Cyber Analysis Methodology to provide consistent analysis and structured framework for actioning threats
Being able to create and implement alerts for your security team to investigate and act on quickly will help reduce your mean time to identify and respond to security incidents. When investigating these alerts, it’s important to follow a consistent and repeatable process to increase efficiencies and prioritize potential automations down the road. ReliaQuest has developed a proprietary Cyber Analysis Methodology, a framework designed to ensure consistency by addressing key questions that must be answered during an investigation. Below is an example of how you can apply a standard process, such as ReliaQuest’s Cyber Analysis Methodology, to accelerate the investigation of AWS CloudTrail events.
Step 1: Event Identification
Anomaly-based alerts are designed to identify activity which is determined to be outside of normal operations. One alert commonly seen in production environments that detects anomalous behavior is when multiple production instances are terminated within a short time frame. This could indicate that an attacker is terminating instances as a type of data destruction attack designed to negatively impact the company’s operations and reputation.
To get a better understanding of how this rule may be logically set up, let’s assume that we want to be notified whenever 20 or more instances are terminated by a single user within 5 minutes.
Rule Logic:
20 Events:
Where the event name is [TerminateInstances OR DeleteInstances]
Where the instance is on [Production Instance List]
With the same source user
Within 5 minutes
Below is an example of an EC2 log that was generated by the user ‘Roboman1’ terminating two AWS instances impacting the AWS account ’0123456789’.
{“Records”: [{ “eventVersion”: “1.0”, “userIdentity”: {“type”: “IAMUser”, “principalId”: “PRINCIPAL_ID”, “arn“: “arn:aws:iam::0123456789:user/Development/Roboman1”, “accessKeyId”: “EXAMPLE_ID”, “accountId“: “0123456789”, “userName“: “Roboman1”}, “eventTime“: “2020-11-06T03:21:39Z”, “eventSource”: “ec2.amazonaws.com”, “eventName“: ” TerminateInstances”, “awsRegion”: “us-east-2”, “sourceIPAddress“: “180.163.251.231”, “userAgent”: ” console.ec2.amazonaws.com”, “requestParameters”: {“instancesSet”: {“items”: [{“instanceId“: “i-2oc7w12”}, {“instanceId“: “i-eob7w13”}]}}, “responseElements”: {“instancesSet”: {“items”: [{ “instanceId“: ” i-2oc7w12″, “currentState“: {“code”: 32, “name”: “shutting-down”}, “previousState“: {“code”: 16, “name”: “running”}, { “instanceId“: ” i-eob7w13″, “currentState“: {“code”: 32, “name”: ” shutting-down”}, “previousState“: {“code”: 16, “name”: “running”}}]}}}]}
Step 2: Initial Artifact Gathering
An artifact is a key piece of data that provides additional details about a security event which could be used to help identify the attacker, victim, or intent of the event. Reviewing the above log provides you several key artifacts that a security analyst could use to begin pivoting on. Investigating key artifacts will help develop a narrative and help identify the level of risk associated with the observed activity. Pulling out some of the artifacts from the above log we see:
“eventTime”: “2020-11-06T03:21:39Z”
“eventName”: ” TerminateInstances”
“sourceIPAddress”: “180.163.251.231”
“userName”: “Roboman1”
“accountId”: “0123456789”
“instanceId”: “i-2oc7w12”
“instanceId”: “i-eob7w13”
“arn”: “arn:aws:iam::0123456789:user/Development/Roboman1”
“currentState”: {“code”: 32, “name”: ” shutting-down”}
“previousState”: {“code”: 16, “name”: “running”}
Step 3: Artifact Analysis
Now that you have identified the artifacts within our TerminateInstances event, begin to pivot on the artifacts to help develop a narrative. There are several key questions that an analyst will need to answer to conduct an effective investigation.
Event Time:
Is the activity occurring off-hours?
Has similar activity been seen in the past occurring around this time?
Are there events occurring outside of the standard time window for this activity?
Event Name:
Were the instances shut down or were they terminated?
What is the normal cadence for instance terminations?
Source IP Address:
Who else within the organization is communicating from this IP?
When did traffic start to or from this IP?
What does OSINT say about this IP that could help us identify whether this is within our geographical operating domain?
Do we expect to see AWS console actions from this IP?
Username:
What does the user(s) have access to or what is their role?
Is this user acting outside of their role or their normal operating time?
Were the user’s privileges/roles/policies recently changed?
Has the user experienced any authentication failures recently?
Has this username been associated with any other threat related activity?
Account ID:
What is the business purpose or function of this AWS account and does the action align?
Instance ID:
When were these instances first stood up?
Has the source user been observed interacting with these instances before the terminate instance event occurred?
Have these instances been observed shutting down in the past and if so when did this occur?
What kind of resource is on the instance?
Were there recent changes to this instance?
Step 4: Additional Artifact Analysis
While conducting your investigation of the artifacts identified within the alerting event, you will undoubtedly come across new artifacts that will need to be investigated further. Being able to filter out the benign activity from the potentially malicious activity comes from experience and familiarization of your environment.
Make sure to be proactive in your environment by having relevant policies, plans, and procedures in place that will help identify when an event goes against the companies standard operating procedures. Having organizational security policies in place will assist in deciding if new artifacts and events should be investigated further.
Step 5: Develop your narrative
Within this scenario, an example narrative for what we have observed so far could be something like:
On November 6th, 2020 at 03:21:39 AM UTC, AWS CloudTrail logs alerted to the user Roboman1 shutting down twenty production instances that are associated with the AWS Account ID ‘0123456789’. An attacker may terminate instances as a type of data destruction attack designed to negatively impact the company’s operations. This alert is designed to detect twenty or more production AWS instances being terminated in a short timeframe.
Pivoting on the user Roboman1 and conducting a historical search over a 7-day period revealed the user’s account activity typically occurred between 7 AM and 7 PM UTC. The alerting activity occurred at 3:21:39 AM suggesting this is not within the normal working hours for the user based on previously observed activity for this account. Pivoting on the authentication activity for the user did not reveal MFA being used for authentication and there were nine failed authentication events that occurred in quick succession at 03:02:10 AM UTC before a successful authentication was observed at 03:02:23 AM UTC.
Conducting OSINT on the Source IP (180.163.251.231) did not reveal any malicious indicators when vetted through GreyMatter Intel, VirusTotal or SANS Threat Feeds*, but the IP was identified as a Chinese-based IP which is outside of the expected geographical region for the user Roboman1. This claim was based on three previous authentication IP geolocations which all resolved to Florida-based IP’s and the regions the company has offices are only located within North and South America. Conducting a historical search on a sample of the instances to better identify a baseline revealed that neither instance has been shut down since standing up on 9/1/2020. The AWS Account ID ‘0123456789’ is associated with Production instances that are used to run several high-priority application backends.*
After you’ve successfully perform an investigation on the user, this is what your recommendation may look like:
We recommend temporarily disabling the user Roboman1’s account until confirmation can be made by their manager that they were authorized to terminate the identified instances as part of authorized business practices. If these AWS instances were not authorized to be terminated, we recommend launching replacement EC2 instances by using the Amazon EBS snapshots or the Amazon Machine Images backups created by the terminated instances, revoking existing access keys, and rotating the credentials for the Roboman1 account while we conduct a deeper investigation into the true origin of these events.
Investigating AWS events with ReliaQuest’s GreyMatter
Conducting pivots to help build the narrative can be time consuming and depending on the technologies incorporated can increase the mean time to resolve an incident due to technology hopping. The main challenge of any analyst is being able to normalize the data in a way that allows you to see the narrative in a heuristic view. Utilizing ReliaQuest GreyMatter, you can normalize all collected data into a common structure to enable visualizations, accurate filtering, and fast searches across the full, aggregated data set, which helps develop a heuristic view of the activity, greatly accelerating response times.



